FoundationDB’s management layer does not communicate job state to other components (Data Distributor, Storage Servers, etc.) by keeping the BulkLoadJobState object alive in memory. Instead, the Management API persists this logical job state in the system keyspace (\xff/…). Once persisted, background actors (particularly in the Data Distributor) can discover and act on this job by reading the corresponding keys.
This process follows a well-defined pattern used by FoundationDB:
1. The Logical Job State Exists Only in Memory
When submitBulkLoadJob is invoked (via the CLI or an API call), it constructs a BulkLoadJobState object:
ACTOR Future<UID> bulkLoadCommandActor(Database cx, std::vector<StringRef> tokens) {
...
state BulkLoadJobState bulkLoadJob = createBulkLoadJob(
jobId,
range,
jobRoot,
jobRoot.find("blobstore://") == 0 ? BulkLoadTransportMethod::BLOBSTORE : BulkLoadTransportMethod::CP);
wait(submitBulkLoadJob(cx, bulkLoadJob));This structure lives only in the Management API process in fdbcli/BulkLoadCommand.actor.cpp during the execution of the actor. Other components cannot directly access it.
To make the job visible cluster-wide, the job must be translated into key/value entries written inside the system keyspace.
2. Materializing the Job: Writing to System Keys via krmSetRange
When a bulk load job is submitted via the Management API, the logic (simplified) looks like this:
ACTOR Future<Void> submitBulkLoadJob(Database cx, BulkLoadJobState jobState) {
...
ASSERT(!jobState.getJobRange().empty());
// Init the map of task states
wait(krmSetRange(
&tr, bulkLoadTaskPrefix, jobState.getJobRange(), bulkLoadTaskStateValue(BulkLoadTaskState())));
// Persist job metadata
wait(krmSetRange(&tr, bulkLoadJobPrefix, jobState.getJobRange(), bulkLoadJobValue(jobState)));
// Take lock on the job range
wait(takeExclusiveReadLockOnRange(&tr, jobState.getJobRange(), rangeLockNameForBulkLoad));
wait(tr.commit());This happens inside a Transaction tr against the system keyspace.
- bulkLoadTaskPrefix and bulkLoadJobPrefix are defined in fdbclient/SystemData.cpp and belong to the system keyspace (\xff/…).
// Bulk loading keys const KeyRef bulkLoadModeKey = "ÿ/bulkLoadMode"_sr; const KeyRangeRef bulkLoadTaskKeys = KeyRangeRef("ÿ/bulkLoadTask/"_sr, "ÿ/bulkLoadTask0"_sr); const KeyRef bulkLoadTaskPrefix = bulkLoadTaskKeys.begin;
2.1 Job range
jobState.getJobRange() is the logical range of user keys the bulk load job is allowed to modify, e.g.:
jobRange = [jobBegin, jobEnd)ASSERT(!jobRange.empty()) ensures the job describes a non-empty region.
2.2 Initializing the task state map
wait(krmSetRange(
&tr, bulkLoadTaskPrefix, jobState.getJobRange(), bulkLoadTaskStateValue(BulkLoadTaskState())));
This call initializes a KeyRangeMap under bulkLoadTaskPrefix in the system keyspace. Conceptually, it says:
For the entire jobRange, the initial BulkLoadTaskState is the default value.
Internally, krmSetRange encodes the logical mapping:
jobRange → BulkLoadTaskState()
into a small set of physical keys under bulkLoadTaskPrefix. This is task metadata, not data payload: it is used later by the Data Distributor and bulk load task engine to coordinate tasks.
2.3 Persisting the job metadata
wait(krmSetRange(&tr, bulkLoadJobPrefix, jobState.getJobRange(), bulkLoadJobValue(jobState)));
Here, BulkLoadJobState jobState (containing jobId, jobRange, jobRoot, phase, transport method, etc.) is serialized via bulkLoadJobValue(jobState) and stored in another KeyRangeMap under bulkLoadJobPrefix.
This effectively materializes the logical job object as system-key metadata:
- Before commit:
jobStateexists only in the Management API process. - After commit:
jobStatealso exists as encoded key/value entries underbulkLoadJobPrefixin the system keyspace.
2.4 Range locking and commit
wait(takeExclusiveReadLockOnRange(&tr, jobState.getJobRange(), rangeLockNameForBulkLoad));
wait(tr.commit());takeExclusiveReadLockOnRangewrites additional system keys (underrangeLockPrefix/rangeLockKeys) to ensure that this job has exclusive ownership of thejobRangefor bulk load purposes.tr.commit()atomically persists:- the initialized task state map,
- the job metadata map,
- and the range lock.
After this commit:
- The Management API is finished with job submission.
- The Data Distributor and other actors can discover the job and task map by reading system keys under:
bulkLoadJobPrefix,bulkLoadTaskPrefix,- and the range lock keys.
The key idea
After the commit, the cluster contains entries like:
ÿ/bulkLoad/job/<encoded begin> → <serialized BulkLoadJobState>
ÿ/bulkLoad/job/<encoded end> → <previous segment’s value>These keys are the authoritative representation of the bulk load job.
3. What krmSetRange Actually Does
krmSetRange on fdbclient/KeyRangeMap.actor.cpp is a helper implementing the canonical KeyRangeMap-on-top-of-FDB pattern:
ACTOR Future<Void> krmSetRange(Transaction* tr, Key mapPrefix, KeyRange range, Value value) {
...
tr->clear([prefix+begin, prefix+end));
tr->set(prefix+begin, value);
tr->set(prefix+end, oldValue);It ensures:
- the logical range [jobRange.begin, jobRange.end) is encoded,
- conflicts are added to maintain serialization,
- map continuity is preserved by restoring the previous value at the end boundary.
Thus, it produces deterministic, transactionally updated metadata about the job.
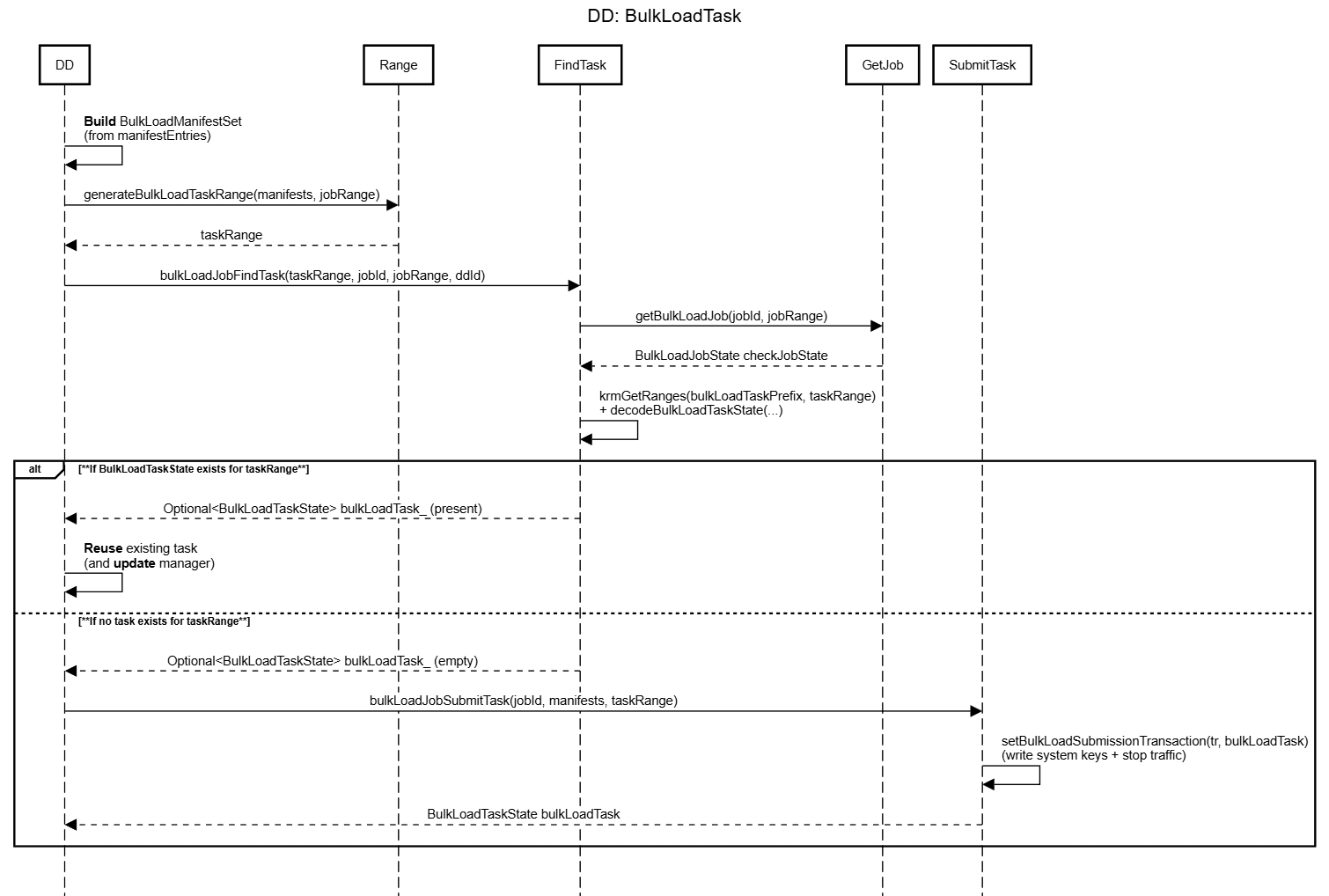
4. Deriving Task Ranges: generateBulkLoadTaskRange
On the Data Distributor side, the job is broken down into tasks based on manifest files. Each task corresponds to a “slice” of the job over a particular key interval.
The helper generateBulkLoadTaskRange defines how a task range is computed:
// A bulkload job can contain multiple tasks. Each task can contain multiple manifests.
// Given a job range, the bulkload task range is defined as the range between the min begin key and the max end key of
// all manifests, overlapping with the maxRange (i.e. the job range).
KeyRange generateBulkLoadTaskRange(const BulkLoadManifestSet& manifests, const KeyRange& maxRange) {
KeyRange manifestsRange = Standalone(
KeyRangeRef(manifests.getMinBeginKey(), manifests.getMaxEndKey()));
return manifestsRange & maxRange; // ensure the task range is within the maxRange
}Key points:
BulkLoadManifestSet manifestsrepresents a set of manifest entries (each describing one or more SST files and the key range they cover).manifests.getMinBeginKey()andmanifests.getMaxEndKey()give the minimum begin key and maximum end key over all manifests in the set.manifestsRangeis the union range of all manifests:manifestsRange = [minBegin, maxEnd)maxRangeis typicallyjobRange.
The task range is computed as:
taskRange = manifestsRange ∩ jobRangeThis ensures:
- The task only covers keys allowed by the job (it cannot extend beyond
jobRange). - Manifests may describe SSTs that contain data outside
jobRange, buttaskRangeis the source of truth for what this task is allowed to load. Storage Servers later usetaskRangeto filter out keys outside the authorized range.
5. Creating Tasks: bulkLoadJobNewTask
Once manifests are known, the Data Distributor uses bulkLoadJobNewTask to create a new task (if necessary):
ACTOR Future<Void> bulkLoadJobNewTask(Reference<DataDistributor> self,
UID jobId,
std::string jobRoot,
KeyRange jobRange,
BulkLoadTransportMethod jobTransportMethod,
std::string manifestLocalTempFolder,
std::vector<BulkLoadJobFileManifestEntry> manifestEntries,
Promise<Void> errorOut) {
state Database cx = self->txnProcessor->context();
state BulkLoadTaskState bulkLoadTask;
state BulkLoadManifestSet manifests;
state double beginTime = now();
state KeyRange taskRange;
ASSERT(!manifestEntries.empty());
try {
// Step 1: Get manifest metadata by downloading the manifest file
wait(store(manifests,
getBulkLoadManifestMetadataFromEntry(
manifestEntries, manifestLocalTempFolder, jobTransportMethod, jobRoot, self->ddId)));
taskRange = generateBulkLoadTaskRange(manifests, jobRange);
// Step 2: Check if the task has been created
Optional<BulkLoadTaskState> bulkLoadTask_ =
wait(bulkLoadJobFindTask(self, taskRange, jobId, jobRange, self->ddId));
if (bulkLoadTask_.present()) {
// The task was not existing in the metadata but existing now. So, we need not create the task.
return Void();
}
// Step 3: Trigger bulkload task which is handled by bulkload task engine
manifests.setRootPath(jobRoot);
wait(store(bulkLoadTask, bulkLoadJobSubmitTask(self, jobId, manifests, taskRange)));
// logging and failure injection omitted for brevity...
} catch (Error& e) {
// error handling...
}
return Void();
}Step 1 – Compute taskRange from manifests and jobRange
The actor starts by:
Downloading/reading manifest metadata:
wait(store(manifests, getBulkLoadManifestMetadataFromEntry( manifestEntries, manifestLocalTempFolder, jobTransportMethod, jobRoot, self->ddId)));Computing the task range:
taskRange = generateBulkLoadTaskRange(manifests, jobRange);
This binds a set of manifests to a specific task range within the global jobRange.
Step 2 – Avoid duplicating tasks: bulkLoadJobFindTask
Before creating a new task, bulkLoadJobNewTask checks whether a task already exists for this (jobId, taskRange):
Optional<BulkLoadTaskState> bulkLoadTask_ =
wait(bulkLoadJobFindTask(self, taskRange, jobId, jobRange, self->ddId));
if (bulkLoadTask_.present()) {
// The task was not existing in the metadata but existing now. So, we need not create the task.
return Void();
}bulkLoadJobFindTask:
- Opens its own transaction.
- Reads task metadata from the system keyspace under
bulkLoadTaskPrefix(and potentially job metadata underbulkLoadJobPrefix). - Interprets these keys as a
KeyRangeMap<BulkLoadTaskState>. - Locates a task that matches
jobIdand overlapstaskRangewithinjobRange.
In this context, bulkLoadJobFindTask is a lookup helper: it prevents duplicate tasks and ensures idempotency in the presence of retries, restarts, or scheduling races.
Step 3 – Creating and submitting the task: bulkLoadJobSubmitTask
If no existing task covers taskRange for this job, a new task is created:
manifests.setRootPath(jobRoot);
wait(store(bulkLoadTask, bulkLoadJobSubmitTask(self, jobId, manifests, taskRange)));bulkLoadJobSubmitTask:
- Builds a new
BulkLoadTaskStateassociated with:jobId,taskRange,- the
manifestsset.
- Persists this state in the system keyspace under
bulkLoadTaskPrefix(again usingkrmSetRangeor related helpers). - Ensures that the bulk load task engine (running in other actors/servers, e.g. StorageServers) will eventually:
- read this task metadata,
- read the SSTs/manifests,
- filter by
taskRange, - apply the writes to the storage engine,
- and mark the task as
completeorerror.
The invariant is:
If a task’s metadata is persisted, the bulk load engine guarantees that the task will eventually complete or fail, and this will be reflected back in the task metadata.
6. How the DD discovers that job and breaks it down into tasks
6.1 Discovering the job from system keys
When submitBulkLoadJob commits, the bulk load job no longer lives only as a BulkLoadJobState object inside the Management API. It also exists as a set of entries under bulkLoadJobPrefix and bulkLoadTaskPrefix in the system keyspace. From the Data Distributor’s point of view, discovering a job simply means:
Open a transaction against the system keyspace and read the KeyRangeMaps under bulkLoadJobPrefix and bulkLoadTaskPrefix for the job range.
Internally, the DD reconstructs a logical view KeyRangeMap<BulkLoadJobState> and KeyRangeMap<BulkLoadTaskState> from those keys and identifies ranges where a job is present and tasks need to be scheduled.
6.2 From job metadata to a job manager
For each discovered job range, the DD instantiates a job manager that owns the coordination logic for that jobId. This manager is responsible for:
- Tracking the job range and the associated
BulkLoadJobStateretrieved frombulkLoadJobPrefix. - Tracking the current
BulkLoadTaskStatemap underbulkLoadTaskPrefix. - Driving the job through its phases (e.g., from
SubmittedtoRunningtoCompletedorFailed).
Crucially, the job manager never keeps the job state only in memory: any decision that matters (new task creation, status changes, errors) is reflected back into the system-key KeyRangeMaps, so that the state is recoverable and observable cluster-wide.
6.3 Deriving task ranges from manifests
Once a job manager knows there is work to do, it needs input manifests. The DD (or a helper actor) downloads or reads manifest metadata from the configured location (jobRoot), building a BulkLoadManifestSet. From this set, the DD computes the effective task range using generateBulkLoadTaskRange:
KeyRange generateBulkLoadTaskRange(const BulkLoadManifestSet& manifests,
const KeyRange& maxRange) {
KeyRange manifestsRange =
Standalone(KeyRangeRef(manifests.getMinBeginKey(), manifests.getMaxEndKey()));
return manifestsRange & maxRange; // clamp to jobRange
}
This definition ensures that:
- The task covers exactly the span of keys described by its manifests.
- The task range never escapes the job’s
jobRange. Any keys in SSTs outside that range will later be filtered out at the Storage Server level.
6.4 Creating tasks and ensuring idempotency
Given a BulkLoadManifestSet and the computed taskRange, the DD follows a three-step pattern to create tasks:
Compute
taskRange.Using
generateBulkLoadTaskRange(manifests, jobRange), the DD binds a set of manifests to a specific sub-range of the job.Check for an existing task.
Before creating a new task,
bulkLoadJobNewTaskcallsbulkLoadJobFindTaskwith(jobId, taskRange). This helper:- Opens a transaction on the system keyspace.
- Rebuilds the
KeyRangeMap<BulkLoadTaskState>underbulkLoadTaskPrefix. - Searches for a task that matches
jobIdand overlapstaskRange.
If such a task exists, the DD concludes that another actor (or a previous retry) already created it and returns without doing anything. This makes task creation idempotent under retries and restarts.
Persist a new task via
bulkLoadJobSubmitTask.If no matching task is found, the DD calls
bulkLoadJobSubmitTask, which:- Builds a new
BulkLoadTaskStatewith thejobId,taskRangeand manifest set. - Persists this state under
bulkLoadTaskPrefixusing the same KeyRangeMap pattern (krmSetRange). - Commits the transaction, making the new task visible to the bulk load task engine.
- Builds a new
Once committed, the task is just metadata in the system keyspace, but that is enough: Storage Servers and other task-engine actors will pick it up, execute it, and update the status back in the map.
7. How Storage Servers execute BulkLoad when the DD marks moves as *_BULKLOAD.
7.1 From *_BULKLOAD moves to task execution
From the Storage Server’s perspective, bulk load execution is triggered by a combination of two signals:
- The presence of task metadata under
bulkLoadTaskPrefix, describing(jobId, taskRange, manifests, state). - A range movement that has been scheduled by the Data Distributor in bulk load mode (often encoded as a special move type, e.g.
_BULKLOAD), indicating that the target Storage Servers should treat this move as a bulk ingress rather than as a stream of transactional mutations.
A bulk-load-aware Storage Server runs actors that:
- Watch the
bulkLoadTaskPrefixKeyRangeMap for tasks whosetaskRangeoverlaps shards it owns. - Filter tasks by state (e.g.,
Submitted/Running). - Start a dedicated “bulk load task engine” to process the manifests and ingest data into the local storage engine.
7.2 Reading manifests and SSTs
Once a Storage Server picks up a task, the bulk load task engine retrieves the manifest information (the same BulkLoadManifestSet described on the DD side) and starts reading the referenced SST files:
- If the transport method is
CP, SST files are expected to be available on local disks or via a copy-based mechanism configured byjobRoot. - If the transport method is
BLOBSTORE, the engine downloads SSTs from a remote blob store into a local temporary folder before ingestion.
In both cases, the Storage Server reconstructs a local view of:
- Which SST files belong to the task.
- The key ranges and approximate sizes of each file.
- Any additional metadata needed by the underlying storage engine (RocksDB, Redwood, etc.).
7.3 Enforcing taskRange and key/value limits
Before actually ingesting data, the bulk load task engine must enforce two critical invariants:
Range safety:
Even if an SST contains keys outside the job’s
jobRange, the task is only allowed to load keys insidetaskRange. The engine iterates over the SST contents and:- Skips keys
< taskRange.beginor≥ taskRange.end. - Only emits mutations for keys within the allowed range.
- Skips keys
Key/value size limits:
FoundationDB enforces global limits on key and value sizes (
KEY_SIZE_LIMITandVALUE_SIZE_LIMIT). A physical bulk load that bypasses the transaction system must still respect these limits. When the engine reads entries from an SST:- If
key.size() > KEY_SIZE_LIMITorvalue.size() > VALUE_SIZE_LIMIT, the task is marked as failed and the job manager will observe the error inBulkLoadTaskState. - This prevents an adversarial SST from injecting oversized entries directly into the storage engine.
- If
With these checks, bulk ingestion preserves the same safety properties that normal transactional writes enforce at the commit path, even though BulkLoad itself lives outside that path.
7.4 Physical vs. logical ingestion in the storage engine
The final step is to translate filtered SST contents into writes on the underlying storage engine:
- On LSM/B-tree style engines that support SST ingestion (e.g. a RocksDB-based backend), the bulk load engine can perform physical ingestion:
- It may rewrite SSTs, drop disallowed keys, and then use the engine’s “ingest external file” API to attach the SSTs directly into the local keyspace.
- This minimizes write amplification: the data is not re-encoded as millions of individual
setoperations.
- On engines that are not shard-aware or do not support native SST ingestion for arbitrary ranges (e.g. Redwood in current versions), bulk load degrades to a logical ingestion:
- The task engine walks the KV entries and issues range updates via
IKeyValueStoremethods such asreplaceRangeor batched writes. - From the Storage Server’s point of view, it is still a bulk operation (done off the commit path), but the storage engine sees a sequence of logical mutations instead of attaching external SST files.
- The task engine walks the KV entries and issues range updates via
In both cases, the Storage Server updates the storage engine in large, streaming batches, respecting taskRange and size limits, and without involving the normal transaction pipeline (proxies, TLogs, etc.).
7.5 Task completion and feedback to the DD
After the ingestion completes (or fails), the Storage Server updates the corresponding BulkLoadTaskState under bulkLoadTaskPrefix to reflect the outcome:
- On success, the task’s phase transitions to a “completed” state and the engine may record statistics such as the number of keys loaded or bytes written.
- On failure, the task records an error code and possibly a reason (e.g., oversized key/value, I/O error, manifest mismatch).
Because this state is persisted in the system keyspace, the Data Distributor’s job manager can:
- Observe progress and completion of tasks.
- Decide whether to retry, split, or abort the job.
- Eventually mark the
BulkLoadJobStateas completed or failed.
Thus, even though bulk load execution happens locally on Storage Servers, job-level orchestration and fault handling remain centralized in the DD through the same metadata layer used for discovery and task creation.